개발
[Python] Pandas 기초 공부 내용 정리 (1)
Yujin Chang
2024. 10. 6. 21:28
import numpy as np
import pandas as pd
s = pd.Series([1, 3, 5, np.nan, 6, 8])
s리스트로 Series를 생성
dates = pd.date_range("20130101", periods=6)
dates2013년 1월 1일부터 시작하여 6개의 날짜 생성
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list("ABCD"))
df6x4 크기의 난수 배열 생성, 인덱스명은 이전 코드의 dates 이용, 컬럼명은 ['A', 'B', 'C', 'D']
[실행 결과]
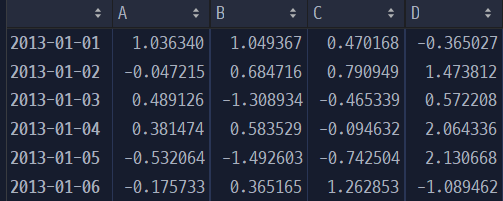
df.head()괄호 안에 아무것도 없으면 데이터프레임의 맨 앞에 있는 5개 행 반환. 만약 괄호 안에 정수가 있다면 해당 개수만큼 반환
df.tail(3)데이터프레임의 맨 끝에 있는 행 3개 반환
df.index데이터프레임의 인덱스 반환
df.columns데이터프레임의 컬럼명 반환
df.to_numpy()Pandas의 데이터프레임을 NumPy의 배열로 형 변환
df.describe()데이터프레임 요약 통계 보고서 출력 (평균, 표준편차, 중앙값 등)
df.T데이터프레임의 행과 열을 서로 바꿈 (Transpose - 전치)
df.sort_index(axis=1, ascending=False)sort_index(): 데이터프레임의 인덱스나 열을 기준으로 정렬
axis=0은 행을 기준으로, axis=1은 열을 기준으로 정렬
ascending=True는 오름차순, False는 내림차순
-> 데이터프레임의 컬럼명을 내림차순으로 정렬한 데이터프레임 반환
[실행 결과]

df.sort_values(by="B")ascending의 디폴트값은 True이므로, 여기선 B열의 값을 기준으로 데이터프레임을 오름차순 정렬한 데이터프레임 반환
df["A"]데이터프레임의 A열에 해당하는 값들만 (인덱스와 함께) 반환